| Variable | Data Type | Definition | Missing Values |
|---|---|---|---|
| PersonAge | int64 | Age of the borrower | 0 |
| PersonIncome | int64 | Income of the borrower | 0 |
| PersonHomeOwnership | object | Home ownership of the borrower | 0 |
| PersonEmpLength | float64 | Employment length of the borrower | 887 |
| LoanIntent | object | Intention of the loan | 0 |
| LoanGrade | object | Loan grade | 0 |
| LoanAmnt | int64 | Amount of the loan (USD) | 0 |
| LoanIntRate | float64 | Loan interest rate | 3095 |
| LoanStatus | int64 | Loan status (0 – not defaulted, 1 – defaulted) | 0 |
| LoanPercentIncome | float64 | Loan percentage of income | 0 |
| PreviousDefault | object | If the borrower has defaulted before | 0 |
| CredHistory | int64 | Credit history length | 0 |



1. Why Predicting Defaults Matters More Than Ever
Access to credit plays a big role in helping people grow businesses, buy property, or manage unexpected costs. But from the lender’s side, it comes with risk. If a borrower defaults, it can lead to major losses. That’s why being able to accurately predict who’s likely to default is so important. Traditional credit scoring has been the standard, but more recently, machine learning (ML) has shown it can do a better job at making these types of predictions (Yang, 2024).
This project uses real-world loan data to compare the performance of three models: Logistic Regression (LR), Random Forest (RF), and XGBoost. Each model is tested using accuracy, precision, recall, F1-score, and area under the curve (AUC). These metrics help assess how well the models identify defaulters and how reliable their predictions are overall (Saito & Rehmsmeier, 2015).
The project also looks at fairness across different borrower groups to see if the models are biased towards or against certain types of applicants. Combining ML with causal analysis, it aims to give a deeper, more balanced view of credit risk prediction.
2. Exploring Risk: From Patterns to Causal Effects
Prior to conducting the analysis of credit risk, we need to understand and organise the data. For this analysis we will be using a loan defaulting dataset from Kaggle (Tse, 2020), consisting of 12 variables/columns and 32580 observations, illustrated in Table 1.
2.1 Getting to Know the Data: Patterns, Quality, and First Impressions
| Variable | N | Mean | Median | SD | Min | Max |
|---|---|---|---|---|---|---|
| PersonAge | 32409 | 27.7 | 26.0 | 6.2 | 20.0 | 94.0 |
| PersonIncome | 32409 | 65894.3 | 55000.0 | 52517.9 | 4000.0 | 2039784.0 |
| PersonEmpLength | 32409 | 4.8 | 4.0 | 4.0 | 0.0 | 41.0 |
| LoanAmnt | 32409 | 9592.5 | 8000.0 | 6320.9 | 500.0 | 35000.0 |
| LoanIntRate | 32409 | 11.0 | 11.0 | 3.2 | 5.4 | 23.4 |
| LoanPercentIncome | 32409 | 0.2 | 0.2 | 0.1 | 0.0 | 0.8 |
| CredHistory | 32409 | 5.8 | 4.0 | 4.1 | 2.0 | 30.0 |
| PersonHomeOwnership | 32409 | Categorical variable | ||||
| LoanIntent | 32409 | Categorical variable | ||||
| LoanGrade | 32409 | Categorical variable | ||||
| LoanStatus | 32409 | Categorical variable | ||||
| PreviousDefault | 32409 | Categorical variable |
Table 1 and 2 display missing values and summary statistics for all variables. Only PersonEmpLength and LoanIntRate had missing values, with 887 and 3095, respectively. To maintain sample size and address skew, median imputation was used for PersonEmpLength, while LoanIntRate, highly correlated with LoanGrade (see Figure 5), was imputed using regression. Duplicate rows were also removed, reducing the dataset to 32415 observations. Additionally, implausible maximum values for PersonAge and PersonEmpLength (144 and 123) were treated as errors and removed. After filtering, the adjusted maximum values were 94 for PersonAge and 41 for PersonEmpLength, ensuring data integrity.
2.2 How the Data Behaves: Exploring Distributions
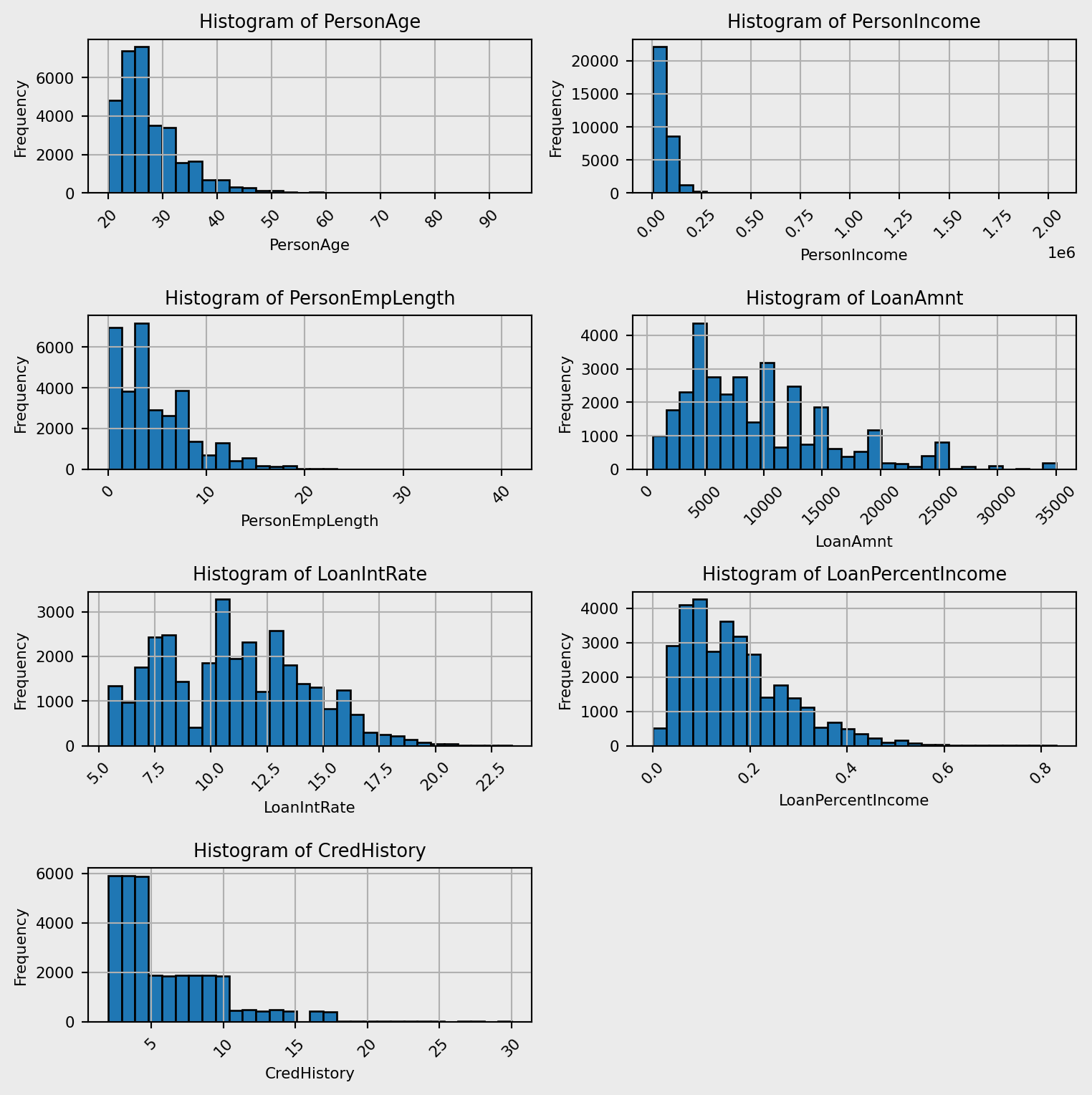
The histograms shown in Figure 1 illustrate the distributions for each numeric variable. All of the variables shown have positively skewed distributions. This is due to individuals with low age likely to have low values in each of these variables. PersonAge, PersonEmpLength and CredHistory have very similar distributions, indicating a potential correlation between these variables.
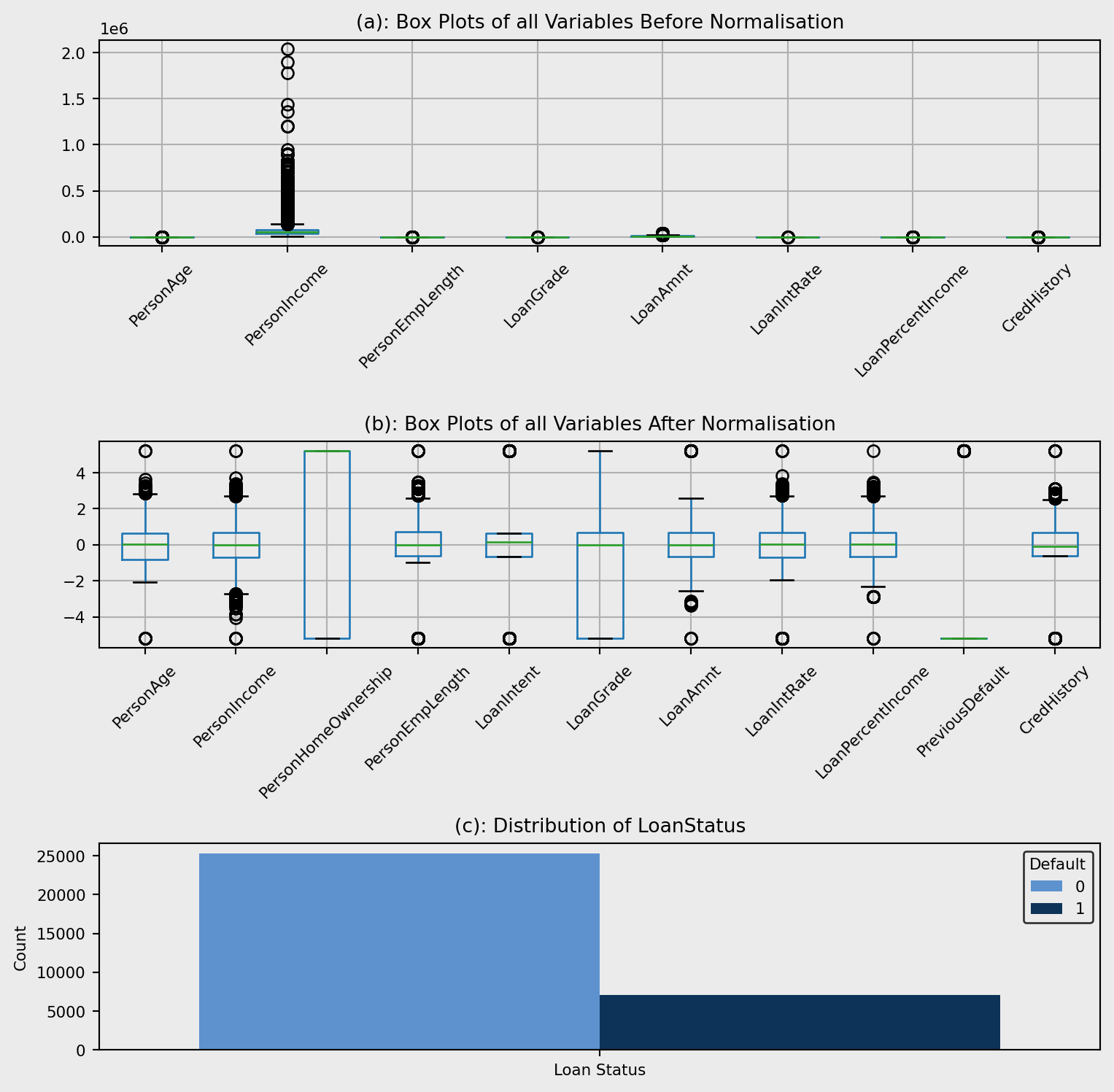
Figure 2(a) shows that the data isn’t scaled proportionally, therefore we need to apply a scaling technique. Due to the skewness of all the variables quantile transformation was deployed with normalised data shown in Figure 2 (b). The plot shows outliers, however there is no reason for these to be errors meaning they will not be removed. For example, the reason for outliers in PersonIncome is due to people earning considerably more than average.
Figure 2(c) demonstrates the distribution of LoanStatus within the dataset. This can cause large impacts on the ML models deployed in the analysis, leading to skewed performance metrics as the models will predict the majority class with high accuracy but the minority class with lower accuracy. To circumvent this issue, I implemented class weighting within my ML models.
2.3 Detecting Relationships and Multicollinearity Among Variables
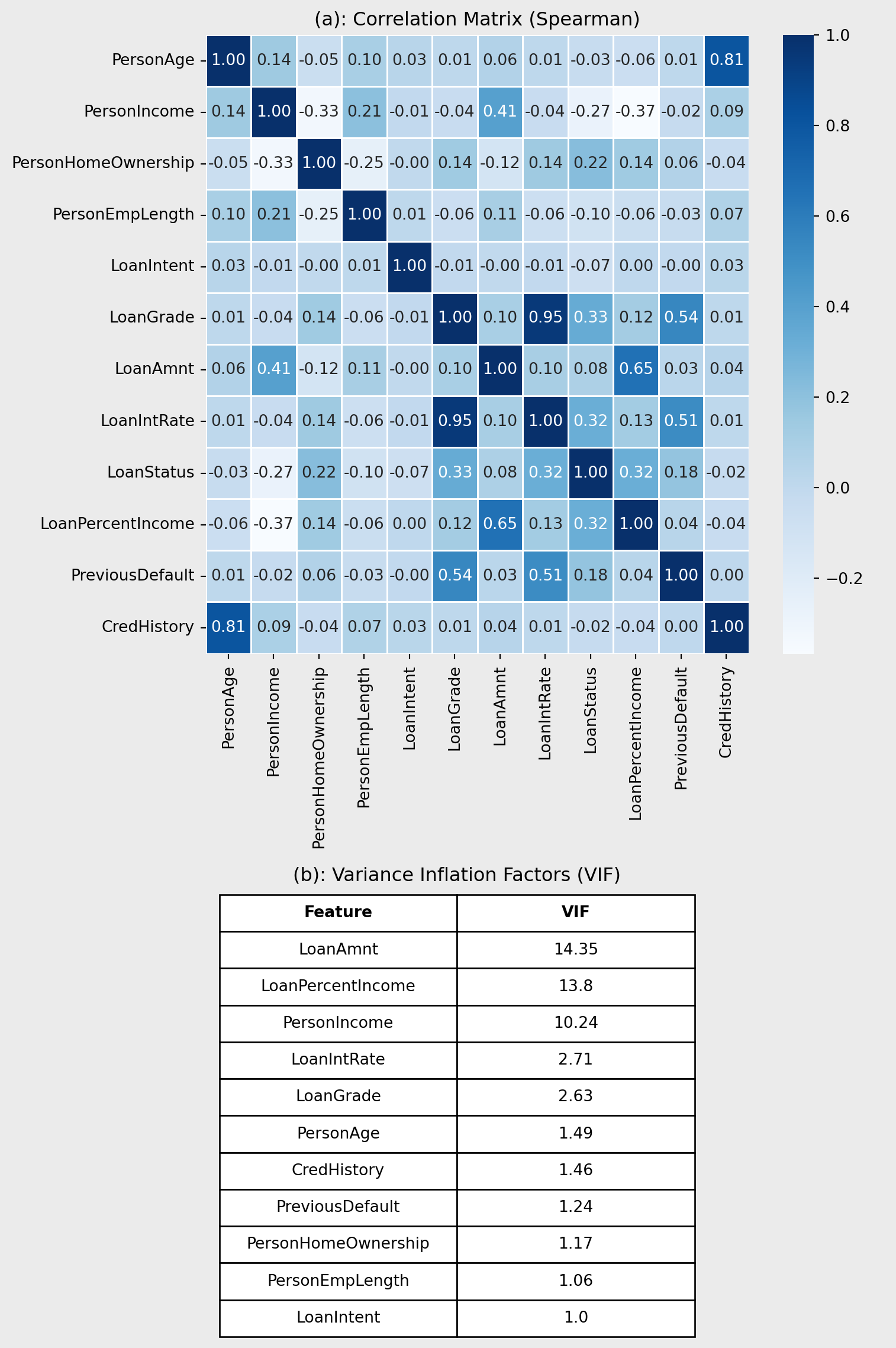
Figure 3(a) shows a correlation plot quantifying the relationships between the variables and the target LoanStatus. LoanGrade and LoanIntRate have a high correlation coefficient (r = 0.95), indicating that they are highly correlated. Also, a similar relationship is shown between PersonAge and CredHistory (r = 0.81). These patterns are expected, older borrowers tend to have longer credit histories, and higher loan grades are typically associated with higher interest rates. While these correlations suggest potential multicollinearity, further assessment using variance inflation factors (VIF) is required.
VIF values for all the variables are shown in Figure 3(b). In contrast to Figure 3(a), LoanGrade, LoanIntRate, PersonAge, and CredHistory have low VIF values, indicating low levels of multicollinearity. However, LoanAmnt, LoanPercentIncome and PersonIncome have VIF values greater than 10 which indicates multicollinearity and actions need to be taken to ensure they don’t affect the models. For the logistic regression, L1 and L2 regularisation was deployed to reduce the effects of multicollinearity. Other models are tree-based and handle multicollinearity, therefore no further processing is needed.
2.4 Moving Beyond Correlation: Searching for Causality
This section explores the heterogeneous impact of PreviousDefault on the likelihood of defaulting again, using a causal forest framework. PreviousDefault was used within this analysis as Hand, D. J., & Henley, W. E. (1997) observed past defaulting status has a strong association with future loan defaults. By estimating conditional average treatment effects (CATEs), we can observe how the effect of previous default varies across individual borrower profiles.
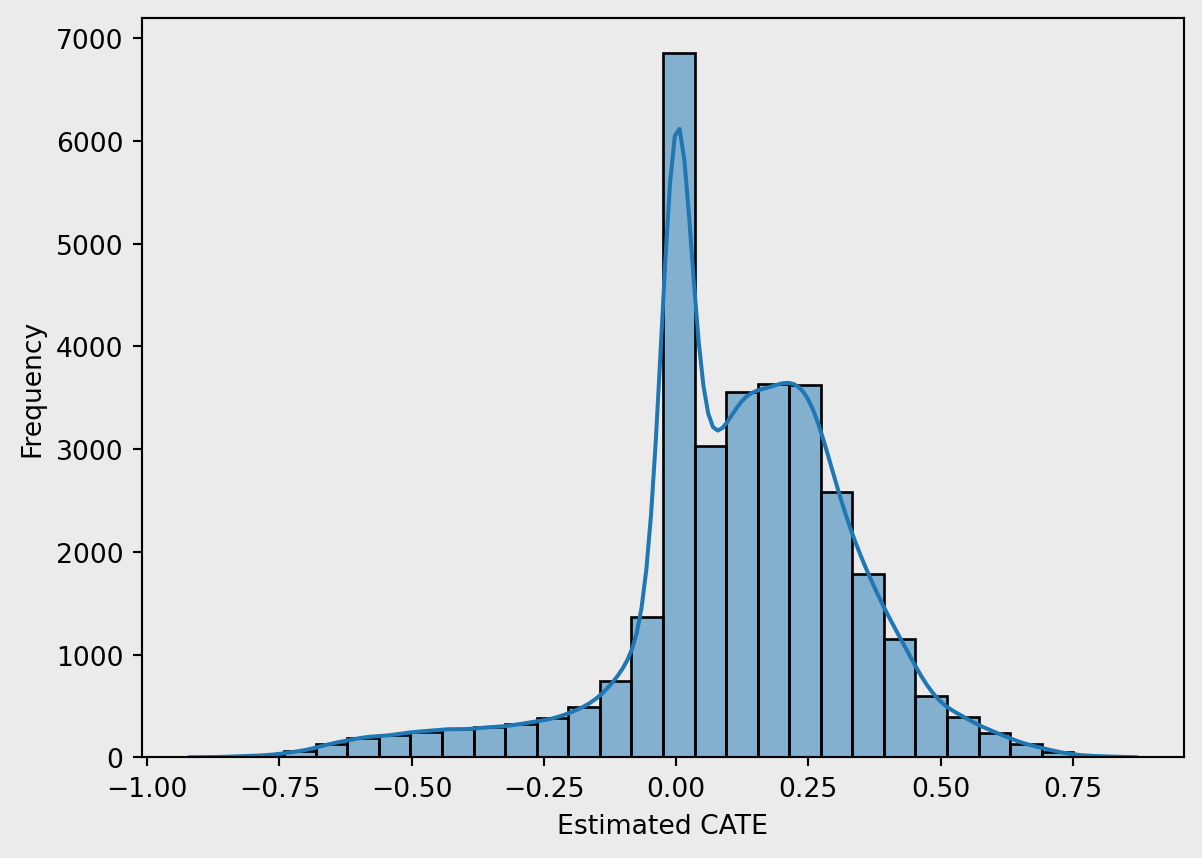
Figure 4 shows estimated CATEs, revealing a negatively-skewed distribution with most values centred near zero. This suggests that, for the majority of borrowers, previous default status has a marginal effect on the likelihood of defaulting again. However, a distinct subgroup exhibits significantly higher CATEs, indicating a substantially increased default risk following a previous default. These individuals may represent vulnerable borrowers, for whom financial distress is a strong predictor of future behaviour. The long right tail emphasises the importance of heterogeneity in treatment effects and justifies the use of a causal forest over average-effect models.
3. Can Machines Predict Who Defaults?
Within this analysis, LR, RF, and XGboost models will be trained to predict LoanStatus using PersonAge, PersonIncome, PersonHomeOwnership, PersonEmpLength, LoanIntent, LoanGrade, LoanAmnt, LoanIntRate, LoanPercentIncome, PreviousDefault and CredHistory.
Before training the models, the dataset was split into train and test sets using an 80:20 ratio to ensure fair evaluation on unseen data. To optimise model performance and avoid overfitting, hyperparameter tuning was conducted using grid search combined with 3-fold cross-validation and L1 + L2 regularisation. To deal with the class imbalance, class weighting was implemented along with prioritising F1-score to reduce financial losses from false negatives but allow the model to remain precise.
3.1 Machine Learning in Action: LR, RF, and XGBoost
The first model deployed was an LR trained on all the standard variables, this model acts as a baseline to compare all more complex models with.
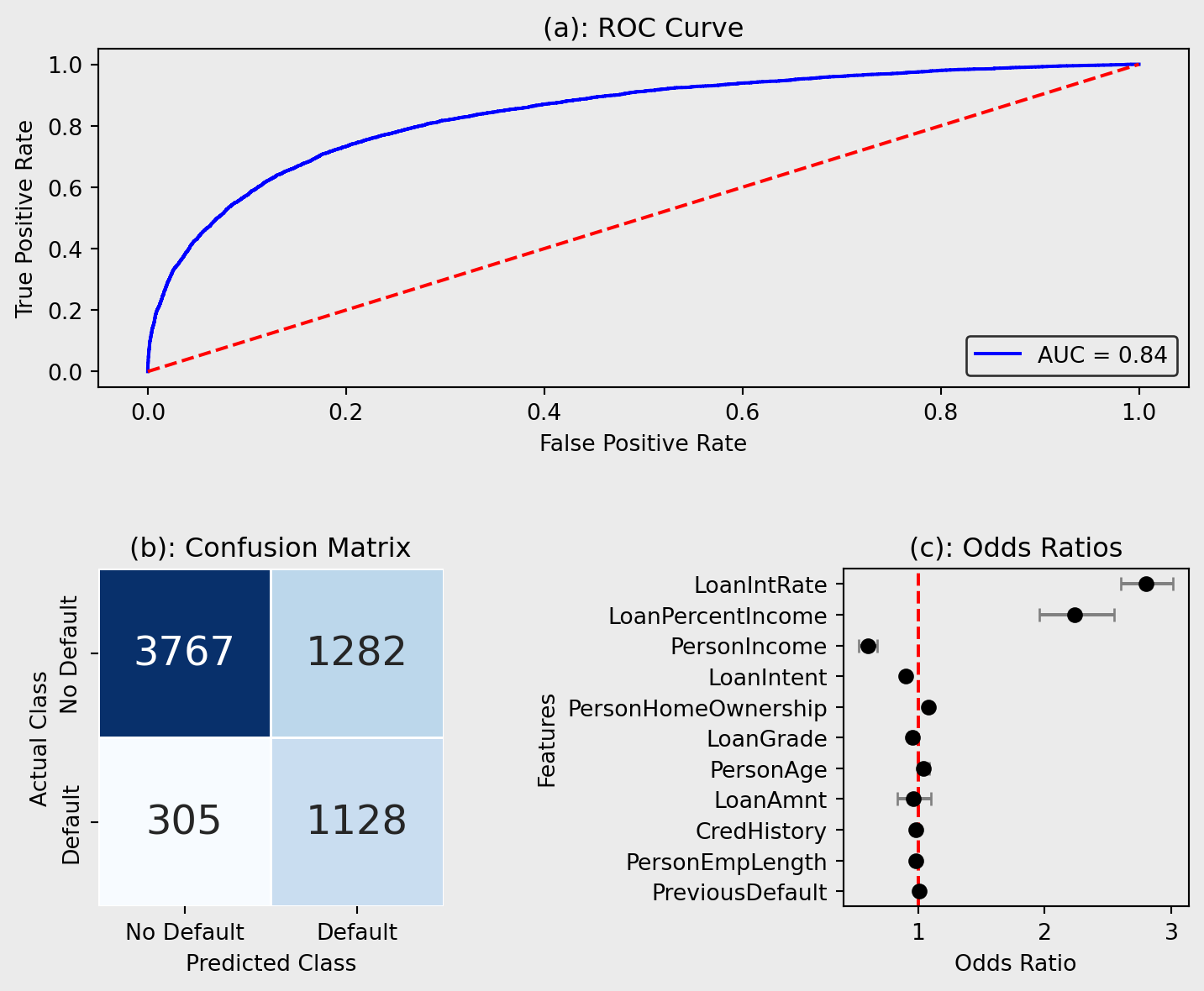
Figure 5(a) shows the ROC curve for the LR model, an indication of the trade-off between sensitivity and specificity of the model. The model achieved an AUC score of 0.842, regarded as considerable (Çorbacıoğlu & Aksel, 2023), indicating solid predictive performance when distinguishing between positive outcomes. The model’s curve lies well above the diagonal reference line (AUC = 0.5), which represents random classification, demonstrating its predictive applications. However, the graph shows room for improvement due to the true positive rate (TPR) remaining below 0.9.
Figure 5(b) visualises the error within the classification model. The matrix reveals that the model correctly identified 3767 non-default cases (true negatives) and 1128 default cases (true positives), demonstrating its ability to capture both classes effectively. However, 1282 non-default cases were misclassified as defaults (false positives), while 305 defaulters were missed (false negatives), which could result in financial loss for lenders.
Figure 5(c) shows the odds ratios for the LR model. The odds ratio indicates the increase in the risk of defaulting for a one-unit increase in that variable and allows for an easy interpretation of the relationships between the individual features and credit risk. The results indicate that LoanIntRate and LoanPercentIncome have the strongest positive associations with default, with odds ratios of 2.797 and 2.234, respectively. This suggests that as interest rates or the proportion of income allocated to the loan increases, the likelihood of default rises significantly. Conversely, PersonIncome has an odds ratio of 0.602, indicating that higher income lowers default probability, consistent with economic expectations.
The second model that was developed and compared with the LR model was an RF, trained on all the standard variables, as they have been shown to have superior performance than LR models (Couronné et al., 2018).
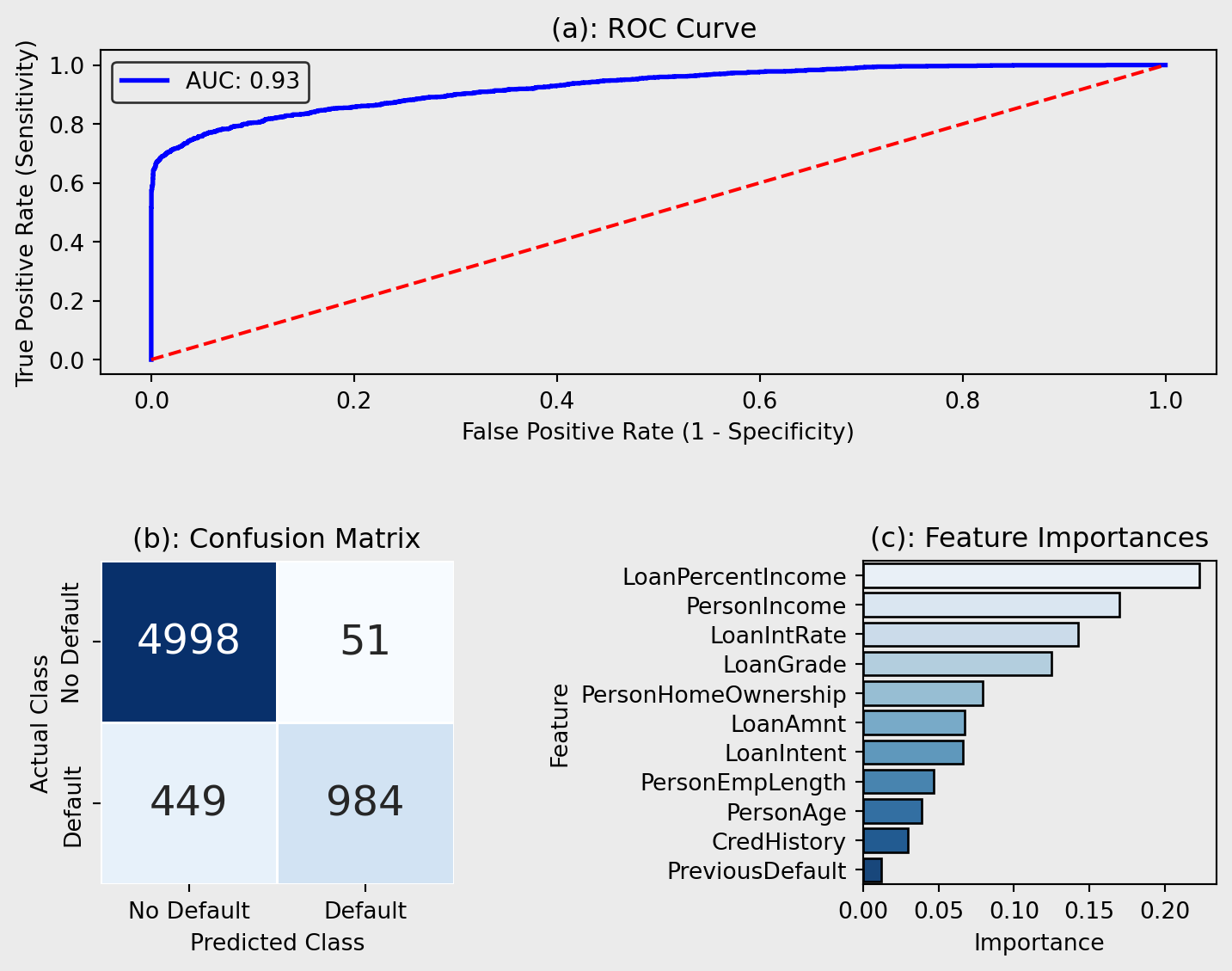
The ROC curve, illustrated in Figure 6(a), showcases its improved classification ability in distinguishing between cases and can be compared to LRs. The model achieved a excellent AUC of 0.927 (Çorbacıoğlu & Aksel, 2023), indicating strong predictive capability and shows that more complex models have the potential to improve credit risk prediction, however highly accurate performance may indicate overfitting.
The confusion matrix (Figure 6(b)) provides a detailed comparison of actual versus predicted default status. In this case, the model correctly predicted non-default for 4998 instances (True Negatives), and correctly identified defaulting for 984 instances (True Positives). However, there were 51 false positives, where the model incorrectly predicted defaulting when the actual class was non-default, and 449 false negatives. This confusion matrix reiterates the improved performance from the LR as the incorrect classification instances have decreased.
Figure 6(c) demonstrates the most influential features when predicting credit risk by visualising feature importance calculated using mean decrease in accuracy. LoanIntRate is the most important feature suggesting that the proportion of income allocated to a loan has the strongest impact on the model’s predictions, supporting the conclusions from the LR which ranked it second. LoanPercentIncome and PersonIncome are also shown to be within the top 3 most important features as they are in the LR model. Conversely, to the LR, the RF shows LoanGrade to have high importance whereas Figure 8 shows it to have very little impact on credit risk for the LR model, potentially attributed to the differences in model architecture.
The third model that I deployed to improve upon the RF model was an XGBoost as they have been shown to reduce potential overfitting and have higher performance and speed than RFs (GeeksforGeeks, 2024).
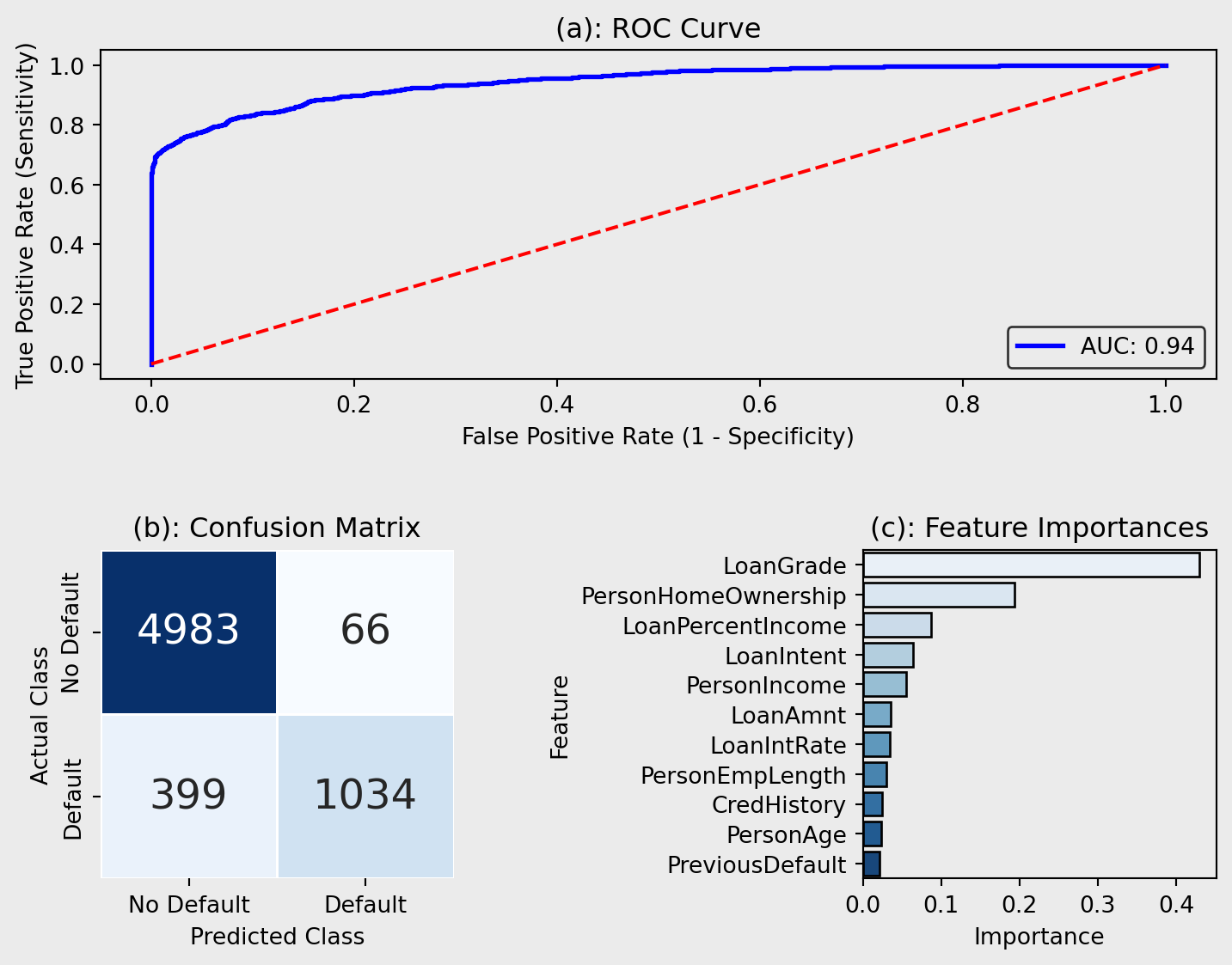
Figure 7(a) visualises the performance of the XGBoost in classifying positive outcomes. This model achieves a slightly higher AUC score than the RF (AUC = 0.944), demonstrating excellent predictive performance (Çorbacıoğlu & Aksel, 2023). Its built-in regularisation, max_depth, min_child_weight, and L1/L2 regularisation, reduces the risk of overfitting despite its complexity.
Figure 7(b) reiterates the increased performance of the XGBoost. XGBoost predicts 50 more true positives than the RF, indicating better sensitivity avoiding potentially revenue losses due to defaulting. The model also has 15 fewer false positives, meaning it incorrectly predicts fewer non-defaulters as defaulters.
Figure 7(c) contradicts the other models (LR and RF), as these models predicted LoanPercentIncome to have less of an impact on the predictions than the XGBoost model. However, similar to the RF and LR model, the XGBoost placed high importance on PersonHomeOwnership reinforcing the notion that the proportion of income allocated to a loan significantly impacts the risk of defaulting. However, LoanGrade ranks higher than in the RF and LR, indicating that home ownership status may play a larger role in how XGBoosts evaluates credit risk.
3.2 Which Model Learns Best? Comparing LR, RF & XGBoost
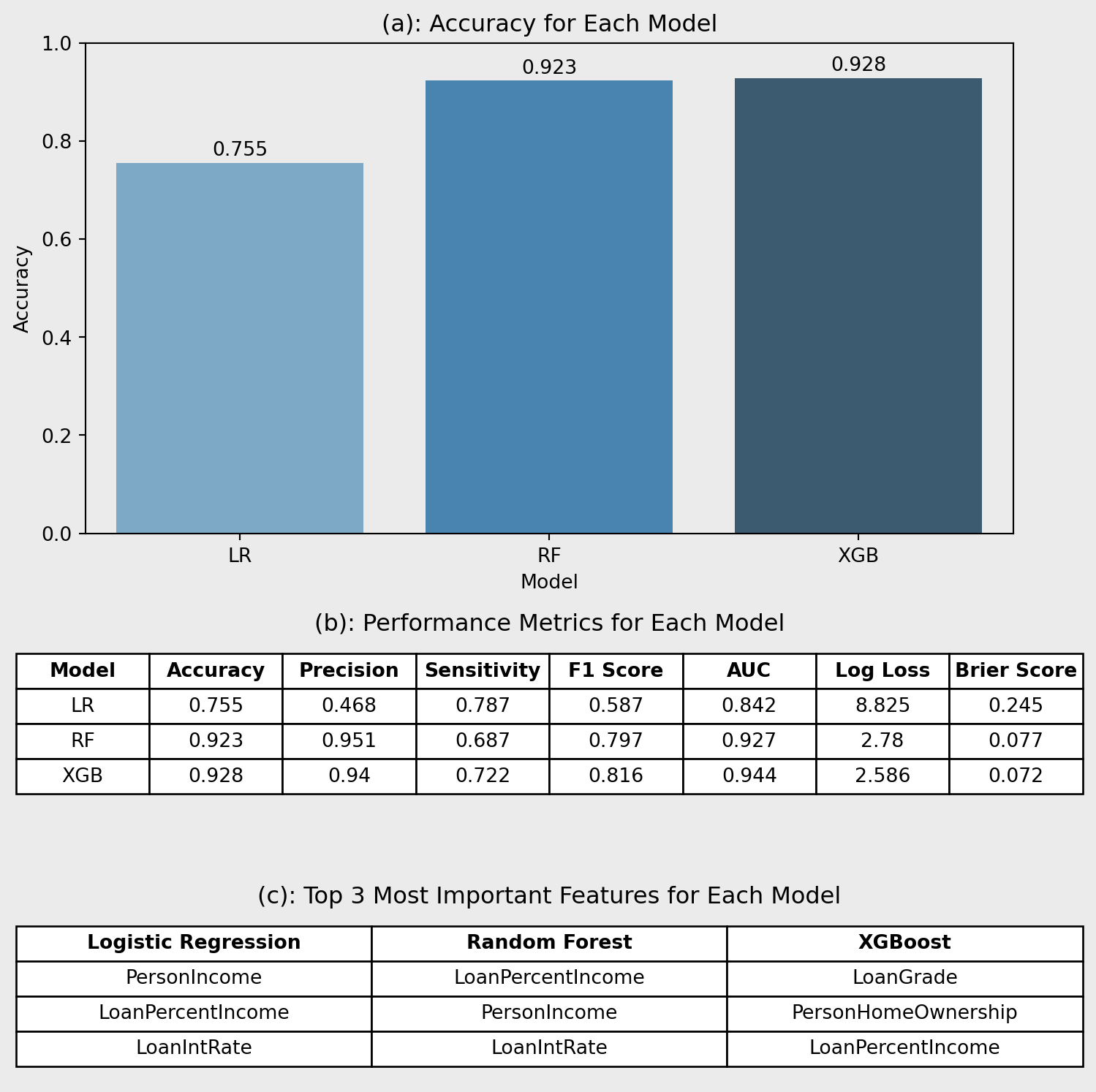
Figure 8(a) shows that XGBoost (0.928) achieves the highest accuracy, closely followed by RF (0.923), while LR lags behind (0.755). However, accuracy alone can be misleading in imbalanced classification tasks such as credit scoring, where minimising the cost of misclassifying defaulters is critical (Hand, D. J., & Henley, W. E., 1997).
Figure 8(b) highlights XGBoost’s overall strength, with the highest AUC (0.944), strong sensitivity (0.722), and F1 score (0.816). RF performs similarly, though with slightly lower recall. LR underperforms across most metrics except sensitivity (0.787) however, precision (0.468) is lacking reducing the applications of this model. Also, LR has the highest log loss (8.825), suggesting poorer probability calibration.
In credit risk analysis, recall is critical. Missing a default is costlier than a false alarm (Hand, D. J., & Henley, W. E., 1997). While LR has competitive recall, XGBoost offers a better balance between recall, precision, and overall performance.
Table 8(c) shows LR focuses on income-related variables, suggesting linear assumptions. Tree-based models prioritise features like LoanGrade and HomeOwnership, capturing non-linear interactions more effectively (Zhou et al., 2002), making them more suited to complex credit risk tasks.
3.3 Who Gets a Fair Deal? Auditing XGBoost’s Default Predictions
| Group | Accuracy | Recall | F1 |
|---|---|---|---|
| Low Income | 0.915 | 0.771 | 0.849 |
| High Income | 0.942 | 0.607 | 0.734 |
| Young (< median age) | 0.928 | 0.741 | 0.831 |
| Old (≥ median age) | 0.928 | 0.703 | 0.801 |
| Renters | 0.929 | 0.814 | 0.878 |
| Homeowners | 0.992 | 0.871 | 0.931 |
| Mortgage | 0.915 | 0.432 | 0.575 |
The fairness audit of the XGBoost model highlights clear differences in recall across borrower subgroups. While overall accuracy remains high, recall is substantially lower for high-income (0.607) and mortgage (0.432) groups, suggesting the model is less effective at flagging defaulters in these categories. In contrast, renters (0.814) and homeowners (0.871) benefit from stronger sensitivity. These gaps may reflect imbalanced data or overlapping traits that obscure risk signals. For instance, mortgagers may combine stable income with high debt, complicating predictions. High-income defaulters may also be underrepresented, reducing model focus. Addressing these differences through subgroup-aware tuning or fairness constraints can improve equity in credit assessments.
3.4 From Models to Meaning: What We Can Learn
This project showed that ensemble learning models like XGBoost and RF can significantly improve how we assess credit risk. Unlike traditional approaches, these models pick up on complex, non-linear relationships in financial data and handle imbalanced datasets much better (Chopra & Bhilare, 2018). Features such as LoanGrade, LoanPercentIncome, and PersonIncome emerged as key predictors, helping lenders make more accurate decisions, reduce misclassifications, and ultimately lower default rates.
However, there are trade-offs. These models are harder to interpret, which can be a challenge in regulated sectors where transparency is important (Rudin, 2019). They also demand more computational power, which might limit access for smaller institutions (Lei, 2025). Without proper tuning, they can overfit on skewed data (Cheng et al., 2021). There’s also the risk of reinforcing biases present in the training data, potentially leading to unfair outcomes in lending (Shah & Davis, 2025). Moving forward, improving explainability, tuning, and fairness will be essential for making these models more practical and trustworthy.
4. Key Takeaways
This project compared the performance of LR, RF, and XGBoost in predicting loan defaults. XGBoost came out on top across all metrics, with the highest accuracy (0.928), AUC (0.944), and F1-score (0.816), showing its strength in capturing complex, non-linear patterns in borrower behavior. RF also performed well, though its slightly lower sensitivity suggests it might miss a few more defaulters. LR trailed behind, limited by its simpler, linear structure.
When looking at what each model focused on, LR leaned heavily on income-based features like PersonIncome and LoanPercentIncome. In contrast, RF and XGBoost picked up broader signals, giving more weight to LoanGrade and PersonHomeOwnership. This suggests that ensemble models offer a more rounded view of credit risk.
To explore how default risk changes across different borrowers, a causal forest was used to estimate conditional average treatment effects (CATEs) for PreviousDefault. While most estimates were close to zero, a clear subgroup showed much higher risk, highlighting the value of causal inference in spotting patterns that average models can miss.
Even the best models have their blind spots. A fairness audit revealed that XGBoost performed unevenly across borrower groups, flagging fewer defaults for some demographics. This reinforces why fairness checks should be built into credit decision systems, to make sure everyone gets a fair shot.
5. References
Cheng, D., Chen, C., Wang, X., & Xiang, S. (2021). Efficient top-k vulnerable nodes detection in uncertain graphs. IEEE Trans. Knowl. Data Eng., 1–1. https://doi.org/10.1109/tkde.2021.3094549
Chopra, A., & Bhilare, P. (2018). Application of ensemble models in credit scoring models. Bus. Perspect. Res., 6(2), 129–141. https://doi.org/10.1177/2278533718765531
Çorbacıoğlu, Ş. K., & Aksel, G. (2023). Receiver operating characteristic curve analysis in diagnostic accuracy studies: A guide to interpreting the area under the curve value: A guide to interpreting the area under the curve value. Turk. J. Emerg. Med., 23(4), 195–198. https://doi.org/10.4103/tjem.tjem_182_23
Couronné, R., Probst, P., & Boulesteix, A.-L. (2018). Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinformatics, 19(1). https://doi.org/10.1186/s12859-018-2264-5
GeeksforGeeks. (2024). Difference between random forest and XGBoost. https://www.geeksforgeeks.org/difference-between-random-forest-vs-xgboost/.
Hand, D. J., & Henley, W. E. (1997). Statistical classification methods in consumer credit scoring: A review. Journal of the Royal Statistical Society. Series A, Statistics in Society, 160(3), 523–541. https://doi.org/10.1111/j.1467-985X.1997.00078.x
Lei, A. (2025). Challenges with ensemble methods. https://www.byteplus.com/en/topic/399838?title=challenges-with-ensemble-methods-in-machine-learning.
Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell., 1(5), 206–215. https://doi.org/10.1038/s42256-019-0048-x
Saito, T., & Rehmsmeier, M. (2015). The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS One, 10(3), e0118432. https://doi.org/10.1371/journal.pone.0118432
Shah, A., & Davis, K. (2025). Mitigating model risk in AI: Advancing an MRM framework for AI/ML models at financial institutions.
Tse, L. (2020). Credit risk dataset. https://www.kaggle.com/datasets/laotse/credit-risk-dataset.
Yang, R. (2024). Machine learning-based loan default prediction in peer-to-peer lending. Highlights in Science, Engineering and Technology, 94, 310–318. https://doi.org/10.54097/qdjd8r65
Zhou, Z.-H., Wu, J., & Tang, W. (2002). Ensembling neural networks: Many could be better than all. Artif. Intell., 137(1-2), 239–263. https://doi.org/10.1016/s0004-3702(02)00190-x